Read Me First!
Before reading this document, it is recommended that Managing Adaptors is read as it contains
information about the entire process of configuring and deploying an Adaptor, whereas this document deals specifically
with the off-the-shelf YOUnite Database (DB) Adaptor.
Quick Start
A quick start guide exists here: YOUnite Database Adaptor Quick Start Guide
Introduction
The YOUnite DB Adaptor is an off-the-shelf adaptor that can scan for changes in a JDBC data source, or listen for changes on a Kafka stream. In addition, the YOUnite DB Adaptor listens for messages from YOUnite and updates the data source with those changes.
The following methods of detecting changes are supported:
| Method | Description |
|---|---|
Timestamp |
Changes are detected based on a timestamp column in a database table. |
Auto Key |
Changes are detected based on new records being added to a table. |
Change Table |
Changes are detected by scanning a "change table" for new records. The "change table" includes the key of the record that changed and what the operation was (INSERT, UPDATE, DELETE). |
Streams |
Changes are detected by listening on a stream (Kafka is currently supported). |
The YOUnite DB Adaptor using Kafka to listen for incoming messages from external data sources.
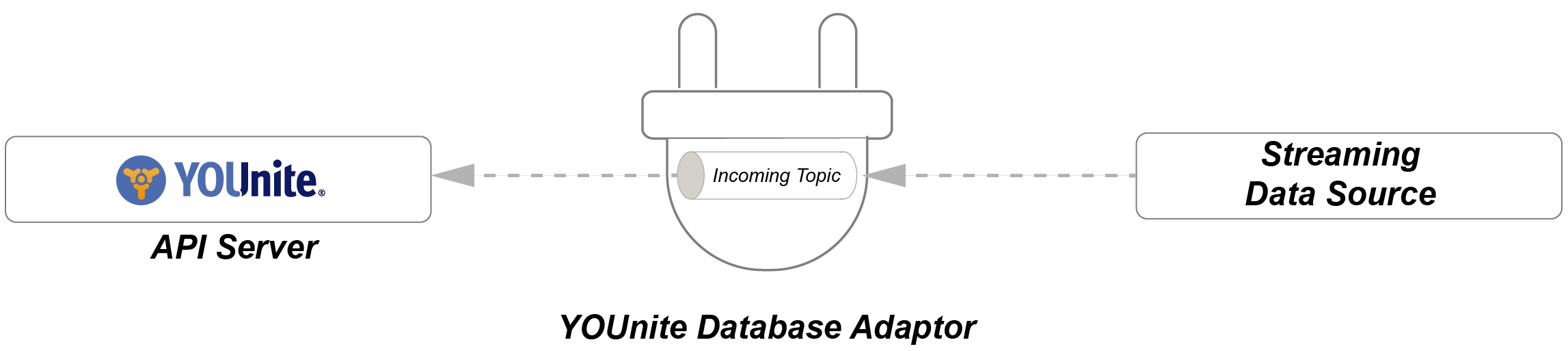
See StreamOptions in the "Adaptor Metadata Configuration" section below.
There are three methods available for scanning database changes: TIMESTAMP, AUTO_KEY, and CHANGE_TABLE. The YOUnite DB Adaptor conducts scans at regular specified time intervals and handles one or more batches during each scan. A scan stops when it runs out of time or a an empty batch is returned:

See Table in the "Adaptor Metadata Configuration" section below.
YOUnite DB Adaptor Processing Service
The YOUnite DB Adaptor includes a processing service that keeps track of:
-
Scanning information (what range of timestamps or keys has been scanned)
-
Incoming records from YOUnite (to prevent infinite loops) and batches of changes identified by a scan.
In addition to providing a place to store this information, the processing service ensures that in the event of a crash, the Adaptor can pick up where it left off and no transactions will be lost.
The processing service is implemented using Mongo DB.
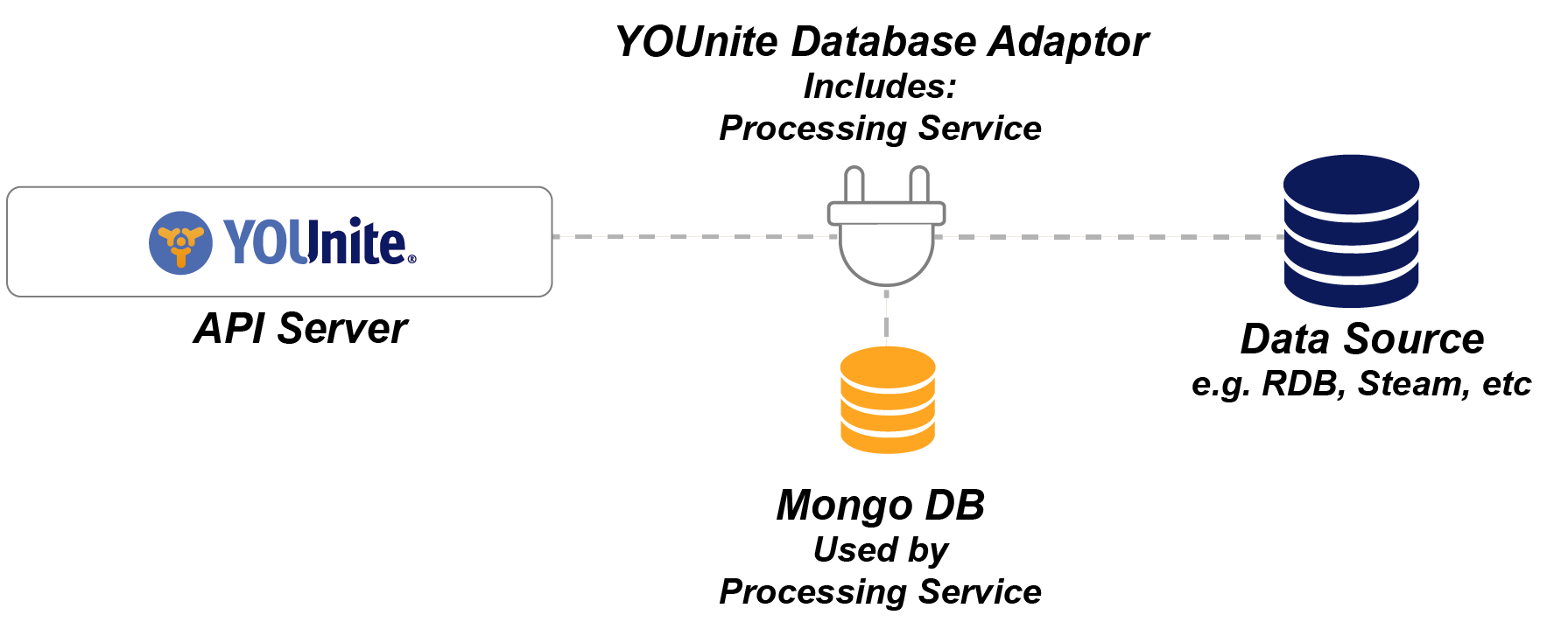
See Processing Service Configuration in the "Service Configuration" section below.
Supported Data Sources
The YOUnite Database Adaptor supports many popular databases using the open source QueryDSL project to assist
with translations to the various SQL dialects of different databases. See the JDBC Configuration section below for a list of databases that are supported.
Even if a database is not in the list of supported databases, it may still be compatible with the YOUnite DB adaptor if:
-
It has a JDBC driver
-
It meets minimal standards:
-
Must be able to return a current timestamp (for timestamp scanning)
-
Must support the usual SELECT, INSERT, UPDATE, DELETE operations
-
Must support IN ( .. ) clause
-
-
If it meets these criteria, the database type that has the same current timestamp function should be used as the rest of the criteria is standard SQL. See the property
template.namein the JDBC Adaptor section. -
If the above does not work, a custom Java class can be developed to implement the proper translations - contact YOUnite for additional information.
In addition to JDBC data sources, the YOUnite DB Adaptor supports MongoDB, NEO4J and Kafka streams.
An important note regarding null handling and missing values
Below are a couple important notes about how the YOUnite DB Adaptor handles null and missing values:
-
If a data event includes a field with the value explicitly set to null, the value in the database will be set to null.
-
If a data event does not include a field, its value will not be set or updated in the database.
Reasons why a field may be excluded:
-
The adaptor that originated the data event did not include data for a field.
-
Data Governance was applied and a field was excluded.
Configuration Overview
An adaptor’s' configuration is stored in the YOUnite API server’s metadata DB and is broken out into two major sections:
-
Adaptor Configuration:
-
Connection information e.g. credentials, message bus URL
-
Other general run-time configuration
-
-
Metadata Configuration:
-
List of datasources (e.g. databases, streams, including the processing service’s Mongo DB)
-
List of tables. Each table contains:
-
A reference to a "datasource"
-
A reference to a domain:version
-
A table name if the datasource is a database
-
Mappings between domain:version properties and datasource properties (e.g. database column)
-
Database and domain:version key specifications and configuration
-
Optional, processing service collection (table) configuration
-
Optional, change scanning configuration
-
The first section "Adaptor Configuration" (not "Metadata Configuration") includes credentials and connection information. The credentials and connection information is generated automatically when the adaptor is created in the YOUnite UI or with the YOUnite API request
POST /zone/<zone-uuid>/adaptors
-
See YOUnite API/Adaptors for more
The credentials and connection information can be retrieved from the YOUnite UI or the response body from the above request and must be configured either as environment variables or included in the adaptor.properties file on the adaptor system (see Creating and Managing Adaptors for more).
The "Metadata Configuration" section is configured using the YOUnite UI or the YOUnite API and forwarded to the Adaptor after it establishes a connection with the YOUnite API server.
Adaptor Configuration
Before starting on this section, read Managing Adaptors.
Required properties:
| Property | Environment Variable | Description | Example Value |
|---|---|---|---|
adaptor.uuid |
ADAPTOR_UUID |
UUID of the adaptor |
|
client.id |
CLIENT_ID |
Username used to connect to message bus |
|
client.secret |
CLIENT_SECRET |
Password used to connect to message bus |
|
message.bus.url |
MESSAGE_BUS_URL |
Message Bus URL |
|
auth.server.url |
AUTH_SERVER_URL |
OAuth Server to validate adaptor access credentials. The YOUnite Server runs an embedded OAuth server that your implementation may be using. By default it runs on port 8080 so, in this case the value would be http://ip-address-of-the-YOUnite-Server:8080 |
Optional properties:
| Property | Environment Variable | Description | Default Value |
|---|---|---|---|
hostname |
HOSTNAME |
Name of the host for the health check endpoint. Note that Kubernetes sets this environment variable by default. |
localhost |
port |
PORT |
HTTP Port to expose for health checks. The health check endpoint at /health, ie GET host:8001/health |
8001 |
concurrency |
CONCURRENCY |
Concurrency for incoming data messages, ie, number of threads that will handle incoming messages. Note that this could lead to messages being processed out of order, though they are guaranteed to be processed in order based on their message grouping (the default is unique ID of the record, ie the DR UUID). |
1 |
ops.concurrency |
OPS_CONCURRENCY |
Concurrency for incoming ops messages, ie, number of threads that will handle incoming messages. These are messages with adaptor status information and metadata, request for stats, shutdown requests. Expressed as a range, ie "1-5" or a single value indicating the maximum (with an implied minimum of 1). |
1 |
assembly.concurrency |
ASSEMBLY_CONCURRENCY |
Concurrency for incoming assembly messages, ie, number of threads that will handle incoming messages. These are federated GET requests. Expressed as a range, ie "1-5" or a single value indicating the maximum (with an implied minimum of 1). |
1 |
session.cache.size |
SESSION_CACHE_SIZE |
JMS session cache size. |
10 |
enable.metrics |
ENABLE_METRICS |
Enable / disable displaying metrics at a given interval. |
true |
metrics.log.interval |
METRIC_LOGS_INTERVAL |
Interval in milliseconds to display metrics. |
3600000 (one hour) |
n/a |
LOG_LEVEL |
Log level for YOUnite logback messages. Applies to |
INFO |
n/a |
ROOT_LOG_LEVEL |
Log level for non-YOUnite logback messages. Applies to |
INFO |
Example:
# Configuration
# Adaptor UUID
adaptor.uuid = 3dfcc03d-e5d4-4d57-9e9b-5c5d2db32f9a
# ClientID and Secret to be used by JMS to connect to the message bus
client.id = 8c9167a6-bb83-4f77-bdfc-1947a946f77b
client.secret = de02e3fa-4b23-46cb-aed6-5665a16e73d3
# Message Bus URL
message.bus.url = tcp://192.2.200.25:61616
# Optional configuration
concurrency = 4
ops.concurrency = 1-4
assembly.concurrency = 2-2
session.cache.size = 10Health Check Endpoint
The adaptor includes a HTTP endpoint to check the health of the adaptor at /health. The default port is 8001.
If the adaptor is healthy, it will return a 200 OK response when querying the endpoint. If it’s not healthy,
it will return a 503 Service Unavailable. For example:
{
"status": "UP"
}In addition, it will return some information about the adaptor such as the status of each service and the uptime. For example, if the employee v1 domain handler is not working, the adaptor might return something like this:
{
"status": "DOWN",
"adaptorService": "UP",
"upTimeMilliseconds": 100000,
"customer:1": "UP",
"employee:1": "DOWN"
}Adaptor Metadata Configuration
The Adaptor Metadata Configuration contains the rest of the configuration for the YOUnite DB Adaptor. This configuration
is stored in JSON format in the metadata of an adaptor. See Managing Adaptors, which
discusses how to assign metadata to an adaptor, which can be done when the adaptor is created or later by updating the
adaptor metadata in the UI or via the API.
You can jump ahead to a full metadata example or, read the specifications below:
Metadata Schema Specification
The top level of the metadata schema contains a list of databases and tables.
{
"databases": { "string" : {DatabaseConnection}, ... },
"tables": [ {Table}, ... ]
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
databases |
Key = data source name, value = |
Object of String → DatabaseConnection |
none |
yes |
tables |
List of table specifications. |
List of Table |
none |
yes |
DatabaseConnection
A DatabaseConnection contains connection information for a database referenced by a Table:
{
"type": "string",
"properties": { "string": object, ... }
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
type |
Database type. JDBC, MONGO, NEO4J, KAFKA, etc or custom type. |
String |
none |
yes |
properties |
List of properties for the connection. |
Object of String → Object |
none |
yes |
Notes:
-
Type is case sensitive and must correspond to a built-in type (JDBC, MONGO, NEO4J, KAFKA, etc) or a custom type.
-
Properties are specific to the database type. See JDBC Configuration, Processing Service Configuration and Kafka Database Metadata Specification for information about what the properties mean.
Table
A Table is the specification of an entity that contains data:
{
"_ Domain and Version _": "",
"domain": "string",
"version": integer,
"_ Data Source _": "",
"dataSource": {DataSource},
"dataColumns": { "string": {Column}, ... },
"readOnly": boolean,
"writeOnly": boolean,
"_ Change Scanning and Key Management _": "",
"scanMethod": "string",
"scanOptions": {ScanOptions},
"primaryKeySpecs": [ {PrimaryKeySpec}, ... ],
"autoKeySpec": {AutoKeySpec},
"timestampSpec": {TimestampSpec},
"streamOptions": {StreamOptions},
"changeTable": {ChangeTable},
"_ Processing Service _": "",
"processingDataSource": {DataSource},
"localIdentifierStoreDataSource": {DataSource}
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
domain |
Data domain name defined in YOUnite that this table maps to. |
String |
none |
yes |
version |
Data domain version defined in YOUnite that this table maps to. |
Integer |
none |
yes |
readOnly |
Set to true if no updates are allowed on this table. |
Boolean |
false |
no |
writeOnly |
Set to true if updates are allowed on this table, but YOUnite is not permitted to |
Boolean |
false |
no |
dataSource |
Data source for this table. |
none |
yes |
|
dataColumns |
Column names and specifications of the data columns in the table that will map to a YOUnite domain version's schema. domain schema. |
Object of String → Column |
none |
yes |
scanMethod |
Scan Method. Allowed values are: |
String |
none |
yes |
scanOptions |
Scan options. Required when |
none |
See ScanOptions below |
|
primaryKeySpecs |
Specifications for primary keys and/or unique keys that uniquely identify records in the table. |
List of PrimaryKeySpec |
none |
yes |
autoKeySpec |
Automatically generated key specifications. Required if |
none |
See AutoKey specification below |
|
timestampSpec |
Timestamp specification. Required if |
none |
See TimeStamp specification below |
|
streamOptions |
Stream options. Required when |
none |
See StreamOptions below |
|
changeTable |
Change table options. Required when |
none |
See ChangeTable below |
|
processingDataSource |
Processing data source for this table. |
none |
See "Notes" below. |
|
localIdentifierStoreDataSource |
Optional data source used to store the mapping between a data record’s UUID in YOUnite and the local identifier at this adaptor. |
none |
See "Notes" below. |
Notes:
-
The domain name and version reference the domain / version defined in YOUnite.
-
The key of
dataColumnsis the name of the column in the table. TheColumnspecification defines what the name of the property is in the data domain version schema. -
dataColumnsmust ONLY include columns that are defined in the specified data domain version in YOUnite. This must include any primary key columns for a PrimaryKeySpec of typeDOMAIN. -
When
writeOnly=true, YOUnite will not be allowed to request data from this table via a Federated GET. However, if the table is set up to perform scanning, it may still send data to YOUnite in the normal way. -
A processing data source is always required unless the adaptor only receives incoming changes from YOUnite for this table, or if ScanMethod =
STREAMandstreamOptions.matchIncoming=false. -
A local identifier store data source is required if the adaptor will be performing "deletion scanning" to look for deleted records. If the adaptor does not require this capability, the local identifier store is not required.
-
See Appendix B for more information about primary key specifications.
DataSource
A DataSource is a reference to a DatabaseConnection with specific database, schema and table information:
{
"name": "string",
"databaseName": "string",
"schema": "string",
"tableName": "string",
"cacheSize": 1000
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
name |
Name of a |
String |
none |
yes |
databaseName |
Database name. |
String |
none |
no* (except for Mongo) |
schema |
Schema name. |
String |
none |
no |
tableName |
Table name. |
String |
none |
yes* (except for Mongo and local identifier stores) |
cacheSize |
Applicable to local identifier store only. The size of the cache in memory of local identifier mappings. |
Integer |
1000 |
no |
Notes:
-
Required / optional parameters may vary depending on the database type. See JDBC Configuration, Processing Service configuration and Kafka Database Metadata Specification for more information on these database connection types.
-
For local identifier stores, the tableName is optional. If not specified, the table name will be
id_store_{table name}_{version}_{adaptor uuid with underscores instead of dashes}. -
If a table name is specified for a local identifier store it MUST be unique and not shared with any other adaptor or with any other table specification.
Column
A Column is the specification of a column in a table (or property in a stream):
{
"source": "string",
"columnType": "string"
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
source |
Name of the column in the domain/version specification in YOUnite. |
String |
See "Notes" below |
no |
columnType |
Column type. Must be one of the following: STRING, LONG, DOUBLE, DATE, LOCAL_DATE, LOCAL_TIME, TIMESTAMP. |
String |
STRING |
no |
Notes:
-
If
sourceis not specified, it will default to the name of the column in the database. -
The
columnTypecorresponds to the Java data type (forTIMESTAMPits in the java.sql data type). -
What’s with all the date types?
-
DATE = an instant in time with millisecond precision relative to a time zone.
-
LOCAL_DATE = a date (no time) with no time zone information.
-
LOCAL_TIME = a time (no date) with no time zone information.
-
TIMESTAMP = a higher precision date with up to nanosecond precision.
-
ScanOptions
The ScanOptions defines specific options for scanning for changes. These are required when using the scanning method of detecting changes.
{
"processorConcurrency": integer,
"maxBatchSize": integer,
"enableIncoming": boolean,
"enableDeletionScan": boolean,
"enableModificationScan": boolean,
"enableProcessor": boolean,
"modScanPriority": double,
"maxModScanTimeMilliseconds": integer,
"processorFullRange": "string",
"scanIntervalMilliseconds": long,
"preloadNextBatch": boolean,
"keyReadBatchSize": integer
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
processorConcurrency |
Concurrency to use when processing a batch of changes identified by a scan. |
Integer |
1 |
no |
maxBatchSize |
Maximum number of changes to be included in a batch to be processed. Note that multiple batches can be run in a single scan (see scanIntervalMilliseconds and maxModeScanTimeMilliseconds). Set this no higher than 60,000. |
Integer |
10,000 |
no |
enableIncoming |
True or false indicating whether incoming changes from YOUnite should be accepted. |
Boolean |
false |
no |
enableDeletionScan |
True or false indicating whether deletion scanning should be performed. |
Boolean |
false |
no |
enableModificationScan |
True or false indicating whether modification scanning should be performed (inserts and updates). |
Boolean |
false |
no |
enableProcessor |
True or false indicating whether processing of batches of changes should be enabled. |
Boolean |
false |
no |
modScanPriority |
Priority of modification scans relative to deletion scans (if both are enabled). |
Double |
1.0 |
no |
maxModScanTimeMilliseconds |
Maximum time in milliseconds to spend scanning for modifications. |
Integer |
5,000 |
no |
processorFullRange |
Range at which a processor is considered full. Can be expressed as a single integer (ie 10) or a range (8-10). See "Notes" below. |
String |
8-10 |
no |
scanIntervalMilliseconds |
Minimum interval in milliseconds at which to perform a scan. |
Long |
1,000 |
no |
preloadNextBatch |
Pre-load a batch of changes, for efficiency, if multiple batches are awaiting processing. |
Boolean |
true |
no |
keyReadBatchSize |
For processes that identify records by primary key, the batch size to use. See "Notes" below. |
Integer |
1,000 / # of columns in primary key |
no |
Notes:
-
By default, all scanning options are disabled (plus allowing incoming changes from YOUnite). This is by design to ensure that only those options that are desired are explicitly enabled.
-
The scanning method of detecting changes is a two step process. First, the primary key and timestamp of changed records is detected and enqueued for processing. Second, the identified changes are processed in timestamp order* (see note #3 below) and sent to YOUnite. These two processes (scan and process) are run in parallel, however, only one scan and one process task can be running at any given time.
-
When
processorConcurrencyis greater than one, changes are not guaranteed to be sent in timestamp order, however, only one batch is processed at a single time, so modifications to specific records are guaranteed to be sent in the order that they are detected. -
When
processorFullRangeis expressed as a range (ie 5-10), the processor is considered "full" when it reaches 10 pending batches and scanning will not resume until the number of pending batches goes below the 5. -
keyReadBatchSizeis used to limit the size of queries (and prevent the system from crashing) for processes that need to read batches of records by primary key. Queries by primary key can get large as they typically involve long IN (… ) clauses or lots of ANDs and ORs - above a certain limit they may cause the system to crash. The default value of 1,000 divided by the number of primary key columns has been found to work well and provide good performance (much better than reading the records one at a time!).
PrimaryKeySpec
A PrimaryKeySpec is the specification of a primary key or unique key. Up to two specifications may be included, one of
type DOMAIN and one of type LOCAL or LOCAL_AUTO.
{
"columns": { "string": {PrimaryKeyValue}, ... },
"type": "string"
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
columns |
Columns that make up the primary or unique key |
none |
yes |
|
type |
Type of primary / unique key. Must be one of DOMAIN, LOCAL or LOCAL_AUTO. See below. |
String |
none |
yes |
Primary Key Types:
-
DOMAIN= A primary / unique key based on values from the data domain version schema. -
LOCAL_AUTO= A primary / unique key that is an auto-incrementing number. One column can be defined for this type of key and it must be of data typeLONG. -
LOCAL= A primary / unique key that is not an auto-incrementing number.
Notes:
-
The key of
columnsis the name of the column in the table. -
It is highly recommended that a
LOCALorLOCAL_AUTOkey is defined if available and if it differs from the values that are included in the data domain schema. See Appendix B for more information about primary key specifications.
PrimaryKeyValue
A PrimaryKeyValue is the specification of a column that is part of a primary key specification.
{
"columnType": "string",
"required": boolean
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
columnType |
Column type. Must be one of the following: STRING, LONG, DOUBLE, DATE, LOCAL_DATE, LOCAL_TIME, TIMESTAMP. |
String |
none |
yes |
required |
Is the column required, ie "not null" in the database? |
Boolean |
true |
no |
AutoKeySpec
The AutoKeySpec defines specific options for the AUTO_KEY Scan Method and optionally the CHANGE_TABLE Scan Method.
This method is used for tables that have a non-negative auto-incrementing primary key:
{
"columnName": "string",
"defaultStartKey": long,
"gapDetectionEnabled": boolean,
"gapDetectionTimeout": long
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
columnName |
Column name in the database. |
String |
none |
yes |
defaultStartKey |
When the adaptor runs for the first time, the key it should start with. |
Long |
none |
yes* (See "Notes" below) |
gapDetectionEnabled |
Enable gap detection during scanning. See Appendix A: Gap Detection for a description. |
Boolean |
true |
no |
gapDetectionTimeout |
Time to wait in milliseconds for an auto-incrementing key gap to be resolved if gap detection is enabled. |
Long |
5,000 |
no |
Notes:
-
YOUnite is only capable of handling unsigned auto-incrementing columns with a maximum precision of 64 bits which corresponds to the
longdata type in Java 8. -
defaultStartKeyis required for the Adaptor to begin its first scan, unless (warning, advanced option!! do not attempt unless you know what you’re doing!!) the processing table is manually updated with previous scan information.
TimestampSpec
The TimestampSpec defines specific options for the TIMESTAMP Scan Method. This method is used for tables that have
a column with the date/time that the row was created or modified. The precision of this column may vary, but it must be
a data type that includes a date and optionally a time.
{
"columnName": "string",
"type": "string",
"precision": "string",
"scanStartTime": "string",
"lagTimeMilliseconds": long,
"overlapMilliseconds": long
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
type |
Date / time type. Must be either DATE or TIMESTAMP and corresponds to the data type that is produced by a JDBC query against the database. See "Notes" below. |
String |
DATE |
yes |
precision |
Precision of the column, regardless of type. Must be IMPORTANT: This must exactly match the precision of the timestamp column ( See "Notes" below. |
String |
MILLISECONDS |
no |
setOnAddOrUpdate |
Set the timestamp when adding or updating records. For data sources / tables that don’t have triggers that automatically set the timestamp. The system time of the adaptor will be used to set the timestamp. |
Boolean |
false |
no |
scanStartTime |
When the adaptor runs for the first time, the timestamp must be in ISO-8601 format with optional precision up to a nanosecond: YYYY-MM-DDThh:mm:ss.nnnZ. |
String |
none |
yes* (See "Notes" below) |
lagTimeMilliseconds |
Milliseconds to "lag" behind the current time (as reported by the database) for scanning. |
Long |
0 |
no |
overlapMilliseconds |
Milliseconds to overlap scans to accommodate pending transactions. Recommended! and its important to read all notes in this section (especially "Very Important Notes" above) and the Scan Options below. |
Long |
0 |
no |
Notes:
-
The
DATEtype is capable of millisecond precision and theTIMESTAMPtype is capable of nanosecond precision.DATEshould work for nearly all cases, regardless of the data type in the database, and is recommended. Some databases are capable of higher precision, such as microsecond or even nanosecond precision in which caseTIMESTAMPcan be used. -
If the type is
DATEthe precision may not be finer thanMILLISECONDS. -
The
precisionshould exactly represent the precision of the database column. For example, if it is only capable of representing the date in hours:minutes:seconds, thenSECONDSprecision should be specified. Precision greater thanMINUTESis not supported. -
scanStartTimeis required for the Adaptor to begin its first scan, unless (warning, advanced option!! do not attempt unless you know what you’re doing!!) the processing table is manually updated with previous scan information.
|
Important
|
Very Important Notes Regarding OverlapMilliseconds
|
-
There will typically be a delay between the time a "this record was updated" timestamp is calculated and when it is committed to the database. In fact, for databases that provide transactional support (most of them), it is entirely possible that this old timestamp value could be sitting in an uncommitted transaction for quite some time before it is finally committed to disk. To mitigate this, the
overlapMillisecondsproperty should be set to the maximum amount of time a transaction may be pending before it is committed to disk. -
The higher the value of
overlapMilliseconds, the higher the performance penalty on scanning; however, unless the system has an extremely large number of records, the effect should be minimal as only primary key and timestamp information for overlapping records is read on each scan (and those that have already been processed are discarded). -
Another consideration with overlapping scans should be
maxBatchSizein ScanOptions. It is recommended thatmaxBatchSizebe set to the number of estimated transactions duringoverlapMillisecondsplus the maximum number of changes expected per scan to reduce the number of queries required to find new changes. For example, ifoverlapMillisecondsis set at one hour (or 3,600,000ms), and the database typically sees 5,000 transactions per hour,maxBatchSizeshould be set greater than 5,000 (say at least 6,000 to be safe). If uncertain of what value to set, the default of 10,000 is recommended.
|
Important
|
Very Important Notes Regarding MaxBatchSize and Timestamps
|
Database applications typically use the INSERT statement to create a new record in a database table and each INSERT typically gets a unique timestamp or at most a few INSERTs may have the same timestamp (but not more than a large maxBatchSize).
If the number of rows created or updated in a table with identical timestamps greater than maxBatchSize, an adaptor overflow data event exception will be generated and the batch will be ignored.
This can occur in the following scenarios:
-
A single SQL COPY command with a CSV file with more rows than
maxBatchSize:
COPY your_table(your_table_rows) FROM 'YOUR_LARGE_SQL_FILE' WITH (YOUR_CSV_FORMAT)-
A bulk UPDATE or INSERT larger than
maxBatchSizewere an exact timestamp value is specified e.g.:
UPDATE your_table SET timestamp_column = CURRENT_TIMESTAMP WHERE condition;If this is a possibility, set maxBatchSize to an amount higher than the largest possible batch or use another change scanMethod such as CHANGE_TABLE.
StreamOptions
The StreamOptions defines specific options for streaming service such as Kafka:
{
"concurrency": integer,
"maxDeliveryAttempts": integer,
"redeliveryDelay": long,
"incomingTopic": "string",
"outgoingTopic": "string",
"incomingDataRequestTopic": "string",
"outgoingDataRequestTopic": "string",
"matchIncoming": boolean
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
concurrency |
Number of concurrent Kafka consumers to start, that will listen to incoming messages from Kafka. |
Integer |
1 |
no |
maxDeliveryAttempts |
Maximum number of times to attempt to deliver a message from the Kafka stream to YOUnite before abandoning the message. |
Integer |
5 |
no |
redeliveryDelay |
Delay in milliseconds between redelivery attempts. |
Long |
1,000 |
no |
incomingTopic |
Name of the Kafka topic to poll for incoming messages. If no topic is specified then the adaptor will not listen for messages. |
String |
none |
no* (either incoming or outgoing is required) |
outgoingTopic |
Name of the Kafka topic to send data events received from YOUnite to. If no topic is specified then the adaptor will not listen for YOUnite data events. |
String |
none |
no* (either incoming or outgoing is required) |
incomingDataRequestTopic |
Name of the Kafka topic to poll for incoming messages related to data requests (such as federated GET, or retry of data event exception). |
String |
none |
no |
outgoingDataRequestTopic |
Name of the Kafka topic to send data requests to (such as federated GET, or retry of data event exception). |
String |
none |
no |
matchIncoming |
True or false indicating whether messages from YOUnite that are sent to the outgoingTopic should be matched against messages received on the incomingTopic to prevent an infinite loop. |
Boolean |
True if both an incoming and outgoing topic are specified otherwise false. |
no |
ChangeTable
The ChangeTable defines specific options for the CHANGE_TABLE scan method. Note that these specifications are for the
change table that identifies changes, whereas the other settings in the Table are for the table with the actual data:
{
"autoKeyColumnName": "string",
"defaultStartKey": long,
"changeTypeColumnName": "string",
"dataSource": {DataSource},
"gapDetectionEnabled": boolean,
"gapDetectionTimeout": long
}| Property | Description | Type | Default Value | Required |
|---|---|---|---|---|
autoKeyColumnName |
Name of the auto-incrementing column in the change table. |
String |
none |
yes |
defaultStartKey |
They key the adaptor starts with when the adaptor runs for the first time. |
Long |
none |
yes* (See "Notes" below) |
changeTypeColumnName |
Name of the column in the change table that indicates the type of change that was made. See "Notes" below. |
String |
none |
yes |
gapDetectionEnabled |
Enable gap detection during scanning. See Appendix A: Gap Detection for a description. |
Boolean |
true |
no |
gapDetectionTimeout |
Time to wait in milliseconds for an auto-incrementing key gap to be resolved if gap detection is enabled. |
Long |
5,000 |
no |
Notes:
-
YOUnite is only capable of handling unsigned auto-incrementing columns with a maximum precision of 64 bits which corresponds to the
longdata type in Java 8. -
defaultStartKeyis required for the Adaptor to begin its first scan, unless (warning, advanced option!! do not attempt unless you know what you’re doing!!) the processing table is manually updated with previous scan information. -
changeTypeColumnNameindicates the column in the change table that specifies the type of change made. The values in this column must correspond to the SQL operations INSERT, UPDATE and DELETE, or the first letter of each operation (I, U or D).
Inbound and Outbound Transformations
Inbound and outbound transformations provide utilities for performing data transformations in the DB adaptor on payloads originating from:
-
Source systems (outbound) destined for YOUnite
-
YOUnite (inbound) to source systems
Transformations use a Javascript engine, which follows the ES5 standard for the most part (it’s not fully ES6 compatible).
A full example can be found in the YOUnite Off-the-Shelf Adaptor Transformation Example
Overview
A transformation job includes a list of "steps". There are three types of steps - branch, rest and script:
-
A
branch stepexecutes a script and sets the next step to executed based on the result. -
A
rest stepexecutes a REST request, storing the results as a value in the _requests object named after the name of the step. For example, if the name of the step is get_token, the result is stored in _requests.get_token or _requests['get_token'] (either syntax is valid in JavaScript). The result from the request is stored as an object, so for example if the response has an access_token, it can be accessed by _requests.get_token.access_token. Alternatively, use the custom "path" function to safely get a value from the payload or null if the value cannot be found, ie var token = path(_requests, 'get_token.access_token'). -
A
script stepexecutes some JavaScript. This can be used to set variables, alter the next step that is executed conditionally, set an error condition, etc. Note that a rest step also has the ability to include pre and post-processing scripts.
Special Variables
There are several special variables that are used throughout the processing of the transformation:
-
_record (object): The data record to be transformed. Elements in this object may be added, removed and/or updated and will be returned as the result of the transformation.
-
_action(string): The action that is being performed. This will be POST, PUT, GET or LINK_DR. The most common usage of this would be to skip certain steps on a GET, which is a request for the data record from YOUnite, typically for federated DR assembly. On a GET, you might not want to run certain data quality tools, for example, and instead just return the data as-is. -
_response(string): Response from the last executed REST request, if it was successful. Note that this value is only temporary and will be wiped out each time a new REST request is made. -
_requests(object): Responses to all executed REST requests. When a REST request succeeds, its is parsed and stored by step name is this object. If jsonResponse=true for the REST request, the response will be parsed into an object, otherwise the raw string of the response is stored. -
_error(boolean): A flag indicating whether an error has occurred. This is set automatically if any step fails. It may be updated by any script step to set or unset the error condition. Note that setting the error condition itself does not stop the transformation, the _next_step variable must be set to null to stop the transformation. -
_error_message(string): The error message that should be set whenever _error is set to true. -
_next_step(string): The name of the next step to be performed. For a rest or script step, this is set automatically at the beginning of the step based on the value in successStep and may be modified as needed in scripts performed in the step. If an error occurs during a step (ie the REST request fails or a script causes an exception), this value is changed to the value of errorStep. For a branch step, this value is set to the value of trueStep or falseStep depending on the result of the conditional statement. Setting this value to null will stop the transformation.
Scripting Notes & Tips
-
A script that is executed operates in the same context as the last, therefore any variable assignment in one script can be referenced in a later step.
-
Substitution can be performed in the various parts of a REST request (body, headers, query parameters, etc) by using the ${variable-name} syntax. Paths are supported and will be safely evaluated, returning null if the element does not exist, ie ${_requests.token.access_token} or ${_requests['token']['access_token']}. For more complex scenarios where variable substitution is not enough, use the "pre" to run some code to set up variables for the request, then use variable substitution.
-
By default each transformation step can only be run a single time, to avoid infinite loops. If a step needs to be executed multiple times, its maximumInteractions value can be set to allow this (be careful of infinite loops!!).
Full Adaptor Metadata Example
The following example is an adaptor for the PostgreSQL table customer. A Mongo database is used as the processing
table and the TIMESTAMP method of scanning is used.
{
"databases": {
"mongo": {
"type": "MONGO",
"properties": {
"connectionString": "mongodb://admin:admin@mongo:27017/admin"
}
},
"postgres": {
"type": "JDBC",
"properties": {
"jdbcUrl": "jdbc:postgresql://postgres-db:5432/customers",
"dataSource.password": "mysecretpassword",
"dataSource.user": "postgres",
"maximumPoolSize": "10"
}
}
},
"tables": [
{
"domain": "customer",
"version": 1,
"primaryKeySpecs": [
{
"type": "DOMAIN",
"customer_id": {
"columnType": "STRING",
"required": true
}
},
{
"type": "LOCAL_AUTO",
"id": {
"columnType": "LONG",
"required": true
}
}
],
"timestampSpec": {
"columnName": "updated",
"type": "TIMESTAMP",
"precision": "MICROSECONDS",
"scanStartTime": "2020-01-09T20:42:47.936Z",
"lagTimeMilliseconds": 0,
"overlapMilliseconds": 60000
},
"dataColumns": {
"customer_id": {
"source": "customerId",
"columnType": "STRING",
"updatable": false
},
"first_name": {
"source": "firstName",
"columnType": "STRING"
},
"last_name": {
"source": "lastName",
"columnType": "STRING"
},
"email": {
"source": "email",
"columnType": "STRING"
},
"gender": {
"source": "gender",
"columnType": "STRING"
},
"birth_date": {
"source": "birthDate",
"columnType": "LOCAL_DATE"
},
"phone": {
"source": "phone",
"columnType": "STRING"
},
"address": {
"source": "address",
"columnType": "STRING"
},
"city": {
"source": "city",
"columnType": "STRING"
},
"state": {
"source": "state",
"columnType": "STRING"
},
"zip": {
"source": "zip",
"columnType": "STRING"
},
"service_rep": {
"source": "serviceRep",
"columnType": "STRING"
},
"last_visit": {
"source": "lastVisit",
"columnType": "LOCAL_DATE"
},
"account_balance": {
"source": "accountBalance",
"columnType": "DOUBLE"
}
},
"dataSource": {
"name": "postgres",
"schema": "public",
"tableName": "customer"
},
"processingDataSource": {
"name": "mongo",
"databaseName": "processing"
},
"localIdentifierStoreDataSource": {
"name": "mongo",
"databaseName": "id-store"
},
"scanMethod": "TIMESTAMP",
"scanOptions": {
"processorConcurrency": 4,
"maxBatchSize": 10000,
"enableIncoming": true,
"enableProcessor": true,
"enableModificationScan": true,
"enableDeletionScan": true,
"scanIntervalMilliseconds": 1000
}
}
]
}Service Configuration
JDBC Configuration
When configuring a DatabaseConnection that is of type JDBC, the following are some required and common options
to use in properties:
| Property | Description | Required |
|---|---|---|
jdbcUrl |
JDBC Url for the data source, ie jdbc:postgresql://localhost:5432/customers |
yes |
dataSource.user |
Username to connect to the database as |
usually |
dataSource.password |
Password to use |
usually |
maximumPoolSize |
Connection pool size |
no |
template.name |
Database template name. Leave blank to auto-detect. See Template Names below. |
no |
template.printschema |
Print schema name when running queries? (ie SELECT … FROM public.customer vs SELECT … FROM customer) |
no |
More details on options:
-
HikariCP is used to pool JDBC connections and all of the properties are passed to it with the exception of properties that start with "template." which are used to set certain options in the QueryDSL template used.
-
HikariCP uses properties that start with "dataSource." to configure the JDBC driver. All other properties (except "template." properties) are used to configure HikariCP itself. So in the example above (see Full Adaptor Metadata Example - "databases.postgres") "dataSource.user" and "dataSource.password" are passed to the JDBC driver to connect to the database whereas "maximumPoolSize" is a configuration property of HikariCP.
-
These are the configuration options for templates:
-
template.printschema: true or false to specify whether the schema should be used by SQL queries before table names.
-
template.quote: true or false indicating whether names should be quoted.
-
template.newlinetosinglespace: specifies newlines should be converted to spaces
-
template.escape: specifies a single character that should be used as the escape character.
-
HikariCP documentation can be found here: https://github.com/brettwooldridge/HikariCP
Template Names
QueryDSL templates handle translations for the various SQL dialects. The template.name property can be used to
explicitly use a template (otherwise, if it’s a supported database it should be auto-detected). The following templates
are available:
-
CUBRID
-
DB2
-
Derby
-
Firebird
-
HSQLDB
-
H2
-
MySQL
-
Oracle
-
PostgreSQL
-
SQLite
-
SQLServer2005
-
SQLServer2008
-
SQLServer2012
-
Teradata
If none of these templates matches the data source, the closest one can be chosen and may work. For timestamp scanning it’s important that the template used knows how to retrieve the current timestamp, otherwise the rest of the SQL used to SELECT, INSERT, UPDATE and DELETE records is standard and should be supported by nearly any database.
In addition, custom templates may be generated for sources not listed above. Contact YOUnite for more information.
Dynamically Integrating an JDBC Connector
The YOUnite DB Adaptor is designed to support a wide range of databases through the versatile HikariCP connection pool. However, there are scenarios where specific JDBC drivers required by certain databases or database versions are not directly incorporated into the YOUnite DB Adaptor. To address this situation, users must ensure that the necessary JDBC driver is included when deploying the adaptor, particularly when using the adaptor in different environments.
For implementations requiring a JDBC driver not pre-integrated into the YOUnite DB Adaptor, the required JDBC driver .jar file must be explicitly specified. This is achieved by appending the -classpath <path-to-jar-file> option to the command line when launching the YOUnite DB Adaptor. This ensures that the adaptor can establish a reliable connection pool to the database using HikariCP, leveraging the external JDBC driver.
Given that the YOUnite DB Adaptor operates within a Docker container, the following steps are required to create a suitable Docker image that includes the necessary JDBC driver:
-
Request the latest YOUnite DB Adaptor .jar file from your YOUnite representative
-
Download the required JDBC connector .jar file
-
Build a Dockerfile to create a YOUnite DB Adaptor Docker image
-
Use the Dockerfile to build a YOUnite DB Adaptor Docker image
Below is an example Dockerfile setup:
FROM openjdk:8
# Argument to specify the name of the JAR file for the adaptor
ARG JAR_FILE
# Add the JDBC driver and the YOUnite DB Adaptor JAR file to the container
ADD target/lib /
ADD target/<db-vendor-JDBC.jar> /<db-vendor-JDBC.jar>
ADD target/younite-db-adaptor-<version>.jar /younite-db-adaptor.jar
# Entry point to execute the adaptor, including the necessary classpath settings
ENTRYPOINT ["exec", "java", "$JAVA_OPTS", "-jar", "/younite-db-adaptor.jar", "-classpath", "<path-to-jdbc-jar-file>"]This Dockerfile template uses build arguments to facilitate the dynamic specification of the YOUnite DB Adaptor JAR file. The ADD commands place the necessary libraries and the adaptor JAR into the container. The ENTRYPOINT defines the command used to start the adaptor, incorporating environment variables and options for Java execution, including where to find the JDBC driver on the classpath.
It is crucial to replace <path-to-jdbc-jar-file> and <db-vendor-JDBC.jar> in the ENTRYPOINT command with the actual path to the JDBC driver .jar file within the Docker container. This setup ensures that the YOUnite DB Adaptor can access the database driver needed to connect to the specific database instance, thereby enhancing the adaptor’s flexibility and compatibility with various database technologies.
Neo4J Configuration
When configuring a DatabaseConnection that is of type NEO4J, the following are the options
to use in properties:
| Property | Description | Required |
|---|---|---|
connectionString |
Neo4J Connection string. See https://neo4j.com/developer/java/#driver-configuration |
yes |
username |
For basic authentication, the username |
no |
password |
For basic authentication, the password |
no |
token |
For bearer token authentication, the token |
no |
kerberos |
For kerberos authentication, the base64 encoded ticket |
no |
connectionAcquisitionTimeout |
Connection acquisition timeout in seconds |
no |
connectionLivenessCheckTimeout |
Connection liveness check timeout in seconds |
no |
connectionTimeout |
Connection timeout in seconds |
no |
eventLoopThreads |
Event loop threads |
no |
maxConnectionLifetime |
Maximum connection lifetime |
no |
maxConnectionPoolSize |
Maximum connection pool size |
no |
maxTransactionRetryTime |
Maximum transaction retry time |
no |
userAgent |
User agent |
no |
trustAllCertificates |
Set to "true" to trust all certificates. Not recommended in production. If not specified, or "false", only certificates loaded in the system are trusted. |
no |
encryption |
Set to "true" to use encryption. If "false" or not specified, encryption is not used. |
no |
driverMetrics |
Set to "true" to enable driver metrics |
no |
MongoDB Configuration
When configuring a DatabaseConnection that is of type MONGO, the following are the options
to use in properties:
| Property | Description | Required |
|---|---|---|
connectionString |
Full MongoDB Connection string, including username and password |
yes |
See https://docs.mongodb.com/manual/reference/connection-string/ for information about this connection string.
Processing Service Configuration (MongoDB)
Currently MongoDB is required as the "Processing" service. Most Adaptors require a processing service, however, there are two instances where they do not:
-
When the Adaptor only accepts incoming changes from YOUnite.
-
When the Adaptor is for Kafka streams and has
matchIncomingset to false.
What Does the Processing Service Do?
The processing service keeps track of:
-
Scanning information (what range of timestamps or keys has been scanned)
-
Incoming records from YOUnite (to prevent infinite loops) and batches of changes identified by a scan.
In addition to providing a place to store this information, the processing service ensures that in the event of a crash, the Adaptor can pick up where it left off and no transactions will be lost.
Deploying Mongo DB
When load testing and deploying Mongo DB you may want to take advantage of CPU Advanced Vector Extensions if they are available.
|
Important
|
By default, YOUnite uses MongoDB 4.4.6 since MongoDB 5.0+ requires a CPU with AVX support. If you want to use MongoDB 5.0+, then perform an online search to determine whether your CPU supports AVX, as various operating systems and CPUs have distinct ways of indicating AVX compatibility. If your CPU supports, AVX then you can use the latest version of Mongo DB by making the following change to the Docker Compose file before deploying the processing service: |
Change:
image: mongo:4.4.6To
image: mongoLocal Identifier Store Configuration
The DatabaseConnection for a Local Identifier Store can be of type MONGO or JDBC
for one of the following databases only:
-
PostgreSQL
-
H2
What Does the Local Identifier Store Do?
The Local Identifier Store stores key/value pairs of a data record’s unique UUID in YOUnite and the local identifier
of the data record at the adaptor. This database is automatically populated with data as data events occur. This store is
used by deletion scanning to determine whether a record that once existed has now been deleted.
Processing and Local Identifier Store Example
{
"databases": {
"mongo": {
"type": "MONGO",
"properties": {
"connectionString": "mongodb://admin:admin@mongo:27017/admin"
}
},
...
},
"tables": [
{
...
"processingDataSource": {
"name": "mongo",
"databaseName": "processing"
},
"localIdentifierStoreDataSource": {
"name": "mongo",
"databaseName": "local-id-store"
}
}
]
}Timestamp Scanning
When scanMethod = TIMESTAMP, the timestamp method of scanning will be used for that table. See TimestampSpec and
ScanOptions for information on how to set up timestamp scanning.
Deletion Scanning
Deletion scanning is supported for the TIMESTAMP method of scanning. Since deletions cannot be detected by looking at
timestamps, a separate process is run that checks to see if records that previously existed (based on their presence
in the DR to ID cache) are still in the database.
On larger databases, deletion scanning can take a long time. To ensure that deletion scanning does not interfere with
modification scanning (as the two do not run concurrently, one runs, then the other), there are two ScanOptions that
impact how long the deletion scan can run each time it is invoked:
-
modScanPriorityspecifies how much time should be spent on scanning for modifications vs deletions (i.e. a value of 2.0 means twice as much time on modifications as deletions and a value of 0.5 means half as much time on modifications as deletions). -
maxModScanTimeMillisecondsspecifies how much time a modification scan should run (at maximum). -
scanIntervalMillisecondsspecifies the minimum interval between scans.
How these options relate to deletion scanning:
-
Generally, the amount of time spent on modification scanning, divided by
modScanPriorityis given to deletion scanning. -
If
scanIntervalMillisecondsis not exceeded by modification scanning, the remaining time will be given to deletion scanning (if it needs it). -
If deletion scanning misbehaves and runs for too long it will be penalized on subsequent runs and given less time to ensure that it doesn’t take priority away from modification scanning.
Auto Key Scanning
When scanMethod = AUTO_KEY, the auto-increment key method of scanning will be used for that table. See AutoKeySpec
and ScanOptions for information on how to set up auto key scanning.
Important notes:
-
Auto-incrementing key scanning is useful for data sources that only produce new records and whose prior records never change (such as a log). Detection of modifications to records and deletion of records is not supported.
-
See the Appendix A: Gap Detection for important information regarding gap detection.
Change Table Scanning
When scanMethod = CHANGE_TABLE, the change table method of scanning will be used for that table. See ChangeTable
and ScanOptions for information on how to set up change table scanning.
Notes:
-
Change table scanning must be on an auto-incrementing table with a list of primary key columns and the type of modification. The change table itself should not include the data that was changed, or the complete record. Only the primary key information and the type of change.
-
If AutoKeySpec or TimestampSpec is included in the Table specification, optimizations may be used when reading batches of records based on this information. In this case, the auto-key and/or timestamp of the source table should be included in the change table as well as the primary key columns.
-
See the Appendix A: Gap Detection for important information regarding gap detection.
Change Table Example
The following example is for a table named customer which has a primary key of customer_id but is also identified by an auto-incrementing key id. The syntax below is for PostgreSQL (note: "bigserial" indicates an auto-incrementing key):
-- Customer table
CREATE TABLE customer
(
id bigserial primary key not null,
customer_id varchar(10) unique not null,
first_name varchar(100),
last_name varchar(100) not null
);
-- Customer change table
-- Note the column names from customer (id and customer_id) are named
-- identically with the same data type (this is a requirement!)
CREATE TABLE customer_change_table
(
customer_change_table_id bigserial primary key not null,
id bigint not null,
customer_id varchar(10) not null,
change_type varchar(20) not null
)
-- Function to populate change table
CREATE OR REPLACE FUNCTION update_customer_change_table()
RETURNS trigger
LANGUAGE plpgsql
AS $$
BEGIN
INSERT INTO public.customer_change_table (id, customer_id, change_type)
VALUES(CASE WHEN TG_OP = 'DELETE' THEN OLD.id ELSE NEW.id END,
CASE WHEN TG_OP = 'DELETE' THEN OLD.customer_id ELSE NEW.customer_id END,
TG_OP);
RETURN NEW;
END;
$$;
-- Trigger that calls the function to populate the change table
CREATE TRIGGER customer_changed AFTER UPDATE OR INSERT OR DELETE ON custome
FOR EACH ROW EXECUTE PROCEDURE update_customer_change_table();The metadata would look like this:
{
"databases": {
"mongo": {
"type": "MONGO",
"properties": {
"connectionString": "mongodb://admin:admin@mongo:27017/admin"
}
},
"postgres": {
"type": "JDBC",
"properties": {
"jdbcUrl": "jdbc:postgresql://{postgres-db:5432/customers",
"dataSource.password": "mysecretpassword",
"dataSource.user": "postgres",
"maximumPoolSize": "10"
}
}
},
"tables": [
{
"domain": "customer",
"version": 1,
"primaryKeySpecs": [
{
"type": "DOMAIN",
"customer_id": {
"columnType": "STRING",
"required": true
}
},
{
"type": "LOCAL_AUTO",
"id": {
"columnType": "LONG",
"required": true
}
}
],
"autoKeySpec": {
"columnName": "id"
},
"dataColumns": {
"customer_id": {
"source": "customerId",
"columnType": "STRING"
},
"first_name": {
"source": "firstName",
"columnType": "STRING"
},
"last_name": {
"source": "lastName",
"columnType": "STRING"
}
},
"dataSource": {
"name": "postgres",
"schema": "public",
"tableName": "customer"
},
"processingDataSource": {
"name": "mongo",
"databaseName": "processing"
},
"localIdentifierStoreDataSource": {
"name": "mongo",
"databaseName": "id-store"
},
"scanMethod": "CHANGE_TABLE",
"scanOptions": {
"processorConcurrency": 4,
"maxBatchSize": 10000,
"enableIncoming": true,
"enableProcessor": true,
"enableModificationScan": true,
"enableDeletionScan": true,
"scanIntervalMilliseconds": 1000
},
"changeTable": {
"autoKeyColumnName": "customer_change_table_id",
"defaultStartKey": 1,
"changeTypeColumnName": "change_type",
"dataSource": {
"name": "postgres",
"schema": "public",
"tableName": "customer_change_table"
},
"gapDetectionEnabled": true,
"gapDetectionTimeout": 120000
}
}
]
}Kafka Streams
The YOUnite DB Adaptor can use Kafka as a data source to listen for incoming messages and to send outgoing messages, much like
any other data source, except the ultimate source / destination of the data is not known.
Like other data sources, the adaptor metadata configuration for Kafka includes a database entry (which includes the IP of the server and configuration properties for the consumer / producer) as well as a table entry (which includes column information and the Kafka topics to listen to / send to).
Kafka Message format
Messages sent to/from Kafka follow a common format.
Example:
{
"dr": {
"uuid": "b3f1c201-0c58-4055-8baf-da217b00c81a",
"domainVersionUuid": "fd115b83-06dc-48c3-9a77-27a0567d231f",
"drKeyValues": {
"customerId": "ABC123"
}
},
"id": {
"customerId": "ABC123"
},
"action": "POST",
"transactionUuid": "46856e99-c701-4be4-9de8-4de02c0fcfa0",
"additionalParams": {
"additional": "param"
},
"data": {
"customerId": "ABC123",
"firstName": "Ima",
"lastName": "Customer"
}
}Outgoing Kafka Messages
Messages sent to the outgoing topics will include the following:
-
dr: uuid, domainVersionUuid and drKeyValues -
id: local identifier based on the table specification -
action:POST,PUTorDELETEare sent to theoutgoingTopic. Other requests such asGETare sent to theoutgoingDataRequestTopic. -
data: the actual data of the record, if applicable -
transactionUuid:GETrequests will include thetransactionUuid, which must be included in the message responding to the request. -
additionalParams: Currently not used.
Incoming Kafka Messages
DELETE:
Messages sent to an incoming topic for deleted data records MUST include the following:
-
action: The action code being performed (DELETE) -
one of:
dr uuid,dr key values,idordata. One of these is required to uniquely identify the record.
POST, PUT, GET, etc:
All non-delete messages MUST include the following:
-
action: The action code being performed -
data: The data of the record -
transactionUuid:GETresponses MUST include thetransactionUuid. Not required for other message types.
Optionally, if known, the following may also be supplied. If the local identifier cannot be determined by the data, one of these is required to identify the record:
-
dr: the uuid of the data record -
id: local identifier
Requests on the outgoingDataRequestTopic and incomingDataRequestTopic
For a Kafka adaptor to be able to handle data virtualization (Federated GET) as well as respond to other requests for data
(for example, re-processing data event exceptions), the outgoingDataRequestTopic and incomingDataRequestTopic must be
configured and the application that reads the data from these topics must know how to respond.
In general, responses to messages on the outgoingDataRequestTopic should include all the information from the request,
along with the data of the data record that is being requested.
Example GET request:
{
"dr": {
"uuid": "b3f1c201-0c58-4055-8baf-da217b00c81a",
"domainVersionUuid": "fd115b83-06dc-48c3-9a77-27a0567d231f",
"drKeyValues": {
"customerId": "ABC123"
}
},
"id": {
"customerId": "ABC123"
},
"action": "GET",
"transactionUuid": "46856e99-c701-4be4-9de8-4de02c0fcfa0"
}The response should include all information from the request, plus the data of the record.
If not all information can be passed back, at a minimum transactionUuid MUST be included
for a GET. In addition, unless the record can be uniquely identified by values in data,
one of the following must be supplied to identify the record:
-
dr.uuid -
dr.drKeyValues -
id
Example Response:
{
"dr": {
"uuid": "b3f1c201-0c58-4055-8baf-da217b00c81a",
"domainVersionUuid": "fd115b83-06dc-48c3-9a77-27a0567d231f",
"drKeyValues": {
"customerId": "ABC123"
}
},
"id": {
"customerId": "ABC123"
},
"action": "GET",
"transactionUuid": "46856e99-c701-4be4-9de8-4de02c0fcfa0",
"data": {
"customerId": "ABC123",
"firstName": "Ima",
"lastName": "Customer"
}
}Kafka Database Metadata Specification
A Kafka database configuration has a type of KAFKA and a list of properties that correspond to the configuration
options for the Consumer (for incoming messages - see https://kafka.apache.org/documentation/#consumerconfigs)
and Producer (for outgoing messages - see https://kafka.apache.org/documentation/#producerconfigs).
The only required property is bootstrap.servers, however it is also recommended that auto.offset.reset is set to
specify where the adaptor should start reading from the stream when it starts up. Some properties have default values
and some properties cannot be modified (see the two tables below.)
Note that the only type of serialization supported by the YOUnite DB Adaptor is String serialization
/ deserialization. The key of the message is ignored and the value must be a JSON-encoded String.
Common configuration options and their defaults:
| Property | Description | Default Value | Example |
|---|---|---|---|
bootstrap.servers |
Kafka Server(s) IP address and port information. Required. |
localhost:9092 |
|
auto.offset.reset |
Behavior for the first time the adaptor reads the topic. |
latest |
latest, earliest or none |
isolation.level |
Isolation level. |
read_committed |
read_committed, read_uncommitted |
max.poll.records |
Maximum records to receive in a single poll. |
1,000 |
100 |
max.poll.interval.ms |
Maximum delay between invocation of poll until a Consumer is considered failed and its messages will be rebalanced. |
60,000 |
300,000 |
The following properties cannot be updated:
| Property | Description | Value |
|---|---|---|
group.id |
Identifier of the group the consumer belongs to. This ensures that concurrency and transactional support are allowed and on restart the adaptor will pick up where it left off. |
adaptor:{adaptor UUID} |
enable.auto.commit |
Indicates whether auto commit is enabled. This feature is disabled to ensure transactional support. |
false |
key.serializer |
Serializer for keys of outgoing messages. |
org.apache.kafka.common.serialization.StringSerializer |
key.deserializer |
Deserializer for keys of incoming messages. |
org.apache.kafka.common.serialization.StringDeserializer |
value.serializer |
Serializer for values of outgoing messages. |
org.apache.kafka.common.serialization.StringSerializer |
value.deserializer |
Deserializer for values of outgoing messages. |
org.apache.kafka.common.serialization.StringDeserializer |
Example metadata configuration:
{
"name": "Kafka Adaptor",
"description": "Example of a Kafka database definition",
"metadata": {
"databases": {
"kafka": {
"type": "KAFKA",
"properties": {
"bootstrap.servers": "kakfa-server:9092",
"auto.offset.reset": "earliest",
"max.poll.records": 100
}
}
}
}
}Kafka Table Metadata Specification
A Kafka table specification will have a scanMethod of KAFKA and include streamOptions with configuration information.
Either an incomingTopic or outgoingTopic must be specified as well as changeTypeColumnName.
See StreamOptions for more information about these options.
Metadata example for a Kafka Adaptor:
{
"name": "Kafka Adaptor",
"description": "Example of a Kafka table definition",
"metadata": {
"tables": [
{
"domain": "customer",
"version": 1,
"primaryKeySpecs": [
{
"type": "DOMAIN",
"customer_id": {
"columnType": "STRING"
}
}
],
"dataColumns": {
"customer_id": {
"source": "customerId",
"columnType": "STRING"
},
"first_name": {
"source": "firstName",
"columnType": "STRING"
},
"last_name": {
"source": "lastName",
"columnType": "STRING"
}
},
"dataSource": {
"name": "kafka",
"tableName": "customer"
},
"processingDataSource": {
"name": "mongo",
"databaseName": "processing-customer"
},
"scanMethod": "STREAM",
"streamOptions": {
"concurrency": 4,
"maxDeliveryAttempts": 10,
"redeliveryDelay": 1000,
"incomingTopic": "incoming-customer-topic",
"outgoingTopic": "outgoing-customer-topic",
"incomingDataRequestTopic": "incoming-customer-request-topic",
"outgoingDataRequestTopic": "outgoing-customer-request-topic",
"matchIncoming": true
}
}
]
}
}Custom Data Services
The YOUnite Database Adaptor comes with a number of built-in data sources that it supports. These can be extended by
implementing the DataService interface of the YOUnite Database Adaptor SDK. Typically, the AbstractTableDataService
is implemented as it contains some common functionality for data services.
Contact YOUnite for access to the YOUnite Database Adaptor SDK.
Requirements
-
Implement
DataServiceorAbstractTableDataService -
Include a constructor with the following parameters, in this order:
-
DatabaseTable
-
Map<String, DatabaseConnection>
-
TableIDFactory<?>
-
-
Include a static String ALIAS which can be used to identify the database type, ie
private static final String ALIAS = "JDBC"; -
Copy the JAR file with the custom data service into the docker container in the class path (currently the root directory)
-
Add an environment variable
CUSTOM_CLASS_PATHwith a comma-delimited list of class paths to scan for custom data services. This is REQUIRED or the custom implementation will not be detected.
Example
public class MyDataService extends DatabaseTableDataService {
private static final String ALIAS = "MY_DATA_SERVICE";
public MyDataService(DatabaseTable table, Map<String, DatabaseConnection> databaseConnections, TableIDFactory<?> idFactory) {
super(table, idFactory);
}
// implement abstract methods here ...
}Appendix A: Gap Detection
When scanning a table or change table that has an auto-incrementing key, gap detection is recommended to mitigate the possibility of the scanner missing records that were written to disk out of order or "late". For example, if records 1, 2, 3, 4 and 5 are all committed at the same time, the scanner might detect records 1, 2, 4 and 5 (missing 3) if the commit on record #3 takes longer than the rest. The scanner will think that it has completed all records up through #5 when in fact it missed #3.
To mitigate this problem, gap detection should be turned on to pause scanning up to a specified interval to wait for the missing record to appear.
To turn gap detection on, set these properties in AutoKeySpec for the AUTO_KEY scan method or in ChangeTable for
the CHANGE_TABLE method:
-
gapDetectionEnabled - set to true
-
gapDetectionTimeout - set tot the number of milliseconds to wait for the gap to resolve
Appendix B: Primary Key Specifications Explained
There are three types of primary key specifications: DOMAIN, LOCAL_AUTO and LOCAL.
Typically, one DOMAIN and one LOCAL or LOCAL_AUTO specification should be included, unless they are the same in which
case a single DOMAIN specification is sufficient.
Why have a LOCAL or LOCAL_AUTO primary key?
There are a few reasons why a LOCAL or LOCAL_AUTO primary key may be useful and/or necessary:
-
LOCAL_AUTO primary keys allows for some optimizations in processing data events and scanning for changes.
-
When the DOMAIN primary key is something that can be updated in a system, another identifier is needed that will not change, ie the LOCAL or LOCAL_AUTO primary key.
-
When matching rules are used for a data domain to determine if a record exists already at an adaptor. In this case, YOUnite performs the matching and if a match is found, the data event includes the LOCAL / LOCAL_AUTO primary key information so that the adaptor can find and update the record.
DOMAIN Primary Key Specifications
A DOMAIN primary key specification indicates the column(s) from the data domain schema that are used to uniquely identify
a record in the table. This allows the adaptor to determine whether an incoming record exists in the source system already
or if its a new record.
Note that if no DOMAIN primary key specification is given, there will be no way to determine if an incoming record exists
already unless YOUnite has already been made aware of the linkage and sends that information in the data event. This may
be suitable for systems that only receive new records and do not need to update existing records. On the other hand, if
records do need to be updated, then YOUnite must be made aware of all existing records in the system FIRST before it
can begin processing incoming data events.
LOCAL_AUTO Primary Key Specifications
A LOCAL_AUTO primary key specification indicates the column that is an auto-incrementing number. If such a column exists
for the table, it is highly recommended its primary key specification be included as it makes processing more efficient.
LOCAL Primary Key Specifications
A LOCAL primary key specification indicates the column(s) in the table that uniquely identify a record. At least one of
these columns must not be in the data domain schema, otherwise a DOMAIN primary key specification should be used instead.